At Series A, the founder is almost always the best closer on the team. Not because they are uniquely talented at sales. Because they are the only person who actually understands the product, the customer, and the pitch well enough to run a complete conversation.
That is not a compliment. That is a structural failure.
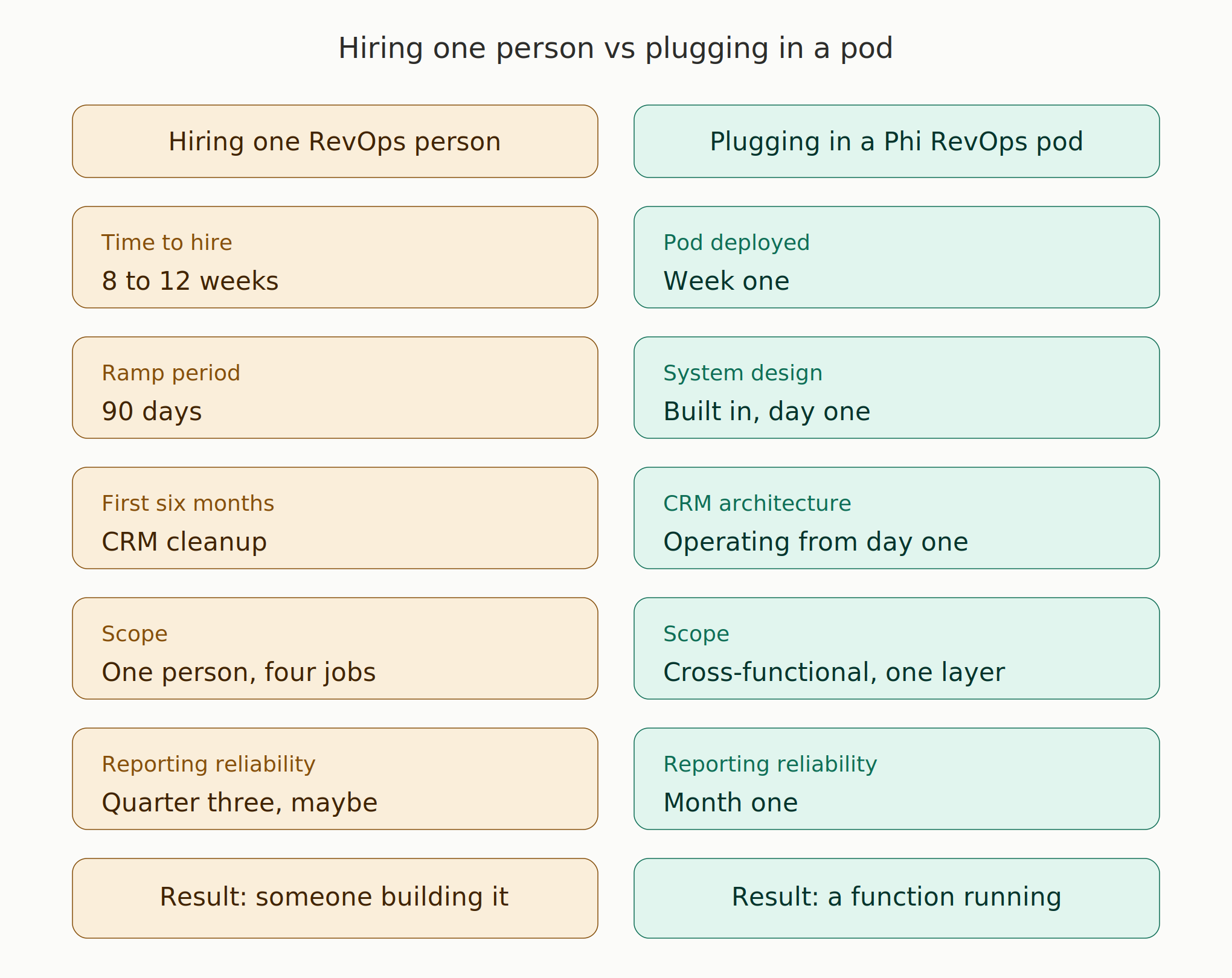
If pipeline depends on your calendar, you do not have a revenue engine. You have a personal service business with a SaaS pricing page.
Why Founder-Led Sales Breaks at the Worst Time
The pattern is consistent across Seed and Series A companies. The founder closes the first 10 to 20 customers. Confidence is high. The board wants to see the number grow. You hire two AEs and an SDR. Three months later, the pipeline is thinner than before you hired them.
Nobody did anything wrong. The problem is that the founder was running on institutional knowledge that never got documented. ICP assumptions that lived in their head. Objection handling that came from 50 conversations nobody else was on. A close that depended on the founder’s credibility, not a repeatable process.
When you hand that off to a new rep, you are not handing off a process. You are handing off vibes. And vibes do not scale revenue.
The question is not how to hire better salespeople. The question is how to build the system they run on. The transition from founder led to team led sales is almost always framed as a people problem. It is almost always an infrastructure problem.
The 5 Systems That Replace the Founder in the Pipeline
There is no single hire that fixes founder-led sales. There is a set of systems that, when they run together, produce pipeline without your involvement. Most companies have one or two of these. Very few have all five.
- ICP definition with teeth. Not “companies with 50 or more employees in logistics.” A real definition: firmographic filters, technographic signals, behavioral triggers, and a clear hypothesis for why this customer buys now. The ICP lives in a document everyone can read, not in the founder’s pattern recognition. When this does not exist, every rep targets a slightly different company and generates completely different results.
- Outbound infrastructure, not outbound activity. Data enrichment that keeps prospect records current. Sequencing logic built around the ICP’s actual buying triggers. Multi-sender LinkedIn outreach through a tool like HeyReach so the volume is not bottlenecked by one inbox. The outbound pod is not a group of SDRs sending emails. It is a system those SDRs run on.
- A defined handoff protocol. The moment a lead moves from SDR to AE is where most pipeline leaks. There is no transfer of context. The AE starts from scratch. The prospect repeats themselves. The deal cools. A real handoff protocol includes a documented summary of the conversation, confirmed next steps, and a CRM record that reflects reality, not aspirations. This is an ops problem, not a people problem, and it belongs inside your sales ops layer.
- Pipeline visibility that does not require a meeting to understand. If you need to ask your head of sales “where are we this month,” you do not have a revenue system. You have a reporting ritual. A real RevOps layer means the CRM reflects actual deal status, attribution is connected to real channels, and the weekly number is not a negotiation. Every person on the revenue team sees the same data. More on what this actually looks like in RevOps best practices that move pipeline.
- A close process that does not require the founder. This is the hardest one. The close usually depends on the founder because the founder can answer any question, handle any objection, and carry the authority of the company. Replacing that requires documented objection handling, a structured discovery framework, and AEs who have been trained on real call recordings, not a one-week onboarding deck. It also requires that someone is actively reviewing calls and coaching. That coaching function is usually the first thing that disappears when the founder steps back.
What This Actually Looks Like: Datatruck
Datatruck came to us at zero ARR. The founder was doing everything. Good product, real market, no system.
We built the ICP definition from scratch. We stood up the outbound infrastructure on Clay for enrichment and Instantly for sequencing. We built the CRM architecture so the pipeline was visible without anyone having to ask. We embedded a sales pod that ran the full process end to end.
The founder stopped being the closer. The system became the closer. This is what moving from founder-led to team-led sales actually looks like in practice.
The Mistake Founders Make Before They Build the System
The default move is to hire a VP of Sales and expect them to build the system. Sometimes that works. More often, the VP inherits the same infrastructure gap the founder had, spends six months trying to figure out what is broken, and leaves before the board runs out of patience.
Knowing how to scale a sales team is not the same as knowing how to build the system underneath it. Most VP hires are operators, not architects. They need a working system to run, not a blank canvas to design.
The sequencing matters. Build the infrastructure first. Then hire the operators. Doing it in reverse is how you burn through $400K and end up with the founder back in the deals.
When You Know the System Is Working
There is a specific moment when the transition from founder-led to team-led sales has actually happened. It is not when you hit a revenue number. It is when a deal closes and you find out about it after the fact.
You were not in the meeting. You did not send the proposal. You did not have to answer the hard question in the final call. The system ran without you and produced a closed deal.
That is the test. Not the pipeline chart. Not the forecast call. Not how many SDRs you have. Whether pipeline generates and converts without your calendar being the critical path.
Scaling B2B sales past founder-led selling is less about adding headcount and more about deciding, deliberately, to build something that does not need you in the room. Most founders know this. Very few actually build it before they desperately need it.
If you are not sure which of the five systems is the weakest link in your current setup, that is usually the right place to start the conversation at Phi.